
С развитием современных технологий в последние десятилетия 20 века произошла и модернизация доступа к печатному и рукописному тексту. Написанный текст был постепенно заменен печатным, который имеет по сравнению с текстом "на бумаге' ряд неоспоримых преимуществ (простое редактирование и форматирование)
С распознаванием сканированного текста связано такое понятие, как OCR. OCR является аббревиатурой от английского "Optical Character Recognition" - оптическое распознавание символов. Речь может идти как о механическом, так и об электронном действии. В большинстве случаев, происходит сканирование документа, который затем анализируется компьютерной программой, которая производит распознавание сканированного текста, отдельных его символов и слов.
OCR– технология распознавания сканированного текста
Технология OCR нашла применение во многих сферах деятельности
Цель и смысл распознавания с помощью OCR сканированного текста заключается в быстрой и дешевой передаче печатного или рукописного содержимого в электронный файл. Важно отметить, что машинное распознавание текста в 20-25 раз быстрее, чем ручное переписывание. OCR можно также использовать для переноса таблиц с номерами в компьютер, что может стать очень эффективным инструментом в любой профессии.
OCR-приложение не может сканировать, однако, может распознавать символы и изображения сканированного текста, создавать обычный текст, который можно в дальнейшем обрабатывать. Оригинал документа на бумаге загружается с помощью сканера. Программа для оптического распознавания сканированного текста позволяет определить отдельные блоки (графики, текст, абзацы и так далее), с последующим распознаванием слов и букв.
Довольно часто случается так, что не все символы получается определить. Система OCR для распознавания сканированного текста использует языковые базы данных для сравнивания сканируемых слов. В случае сходства со словом в словаре, программа может исправить или добавить недостающие символы. В случае, если OCR не в состоянии распознать один символ в слове, это не значит, что слово будет помечено как неопознанное. Если это просто неизвестное слово, то оно вносится в словарь с дополнительной корректировкой.
Новые OCR-программы для распознавания сканированного текста оснащены дополнительными функциями для проверки орфографии (как в MS Word), что позволяет улучшить процесс распознавания
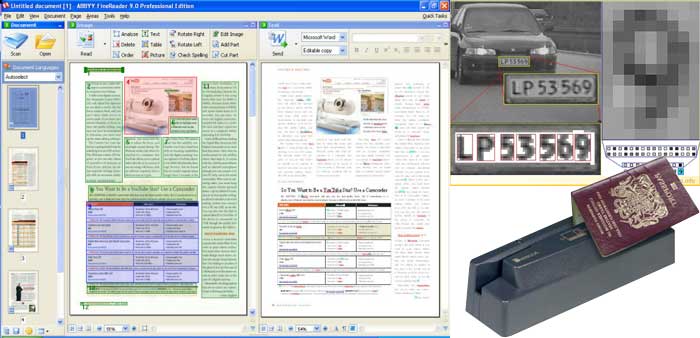
Технология распознавания OCR, как процесс оцифровки, используется как для обычных задач (проверка паспортов), так и при проверке регистрационных знаков транспортных средств. В основном, используется при оцифровке книг и текстов, например, для обеспечения возможности поиска или редактирования. Цифровой контент можно впоследствии редактировать, или же озвучить с помощью преобразования текста в голос. OCR часто используется для распознавания капчи (CAPCHA).
CAPTCHA, как правило, тип цифровой защиты форм, чтобы через них не передавались автоматически генерируемые данные. CAPTCHA представляет собой в основном рисунок, который отображает множество алфавитно-цифровых символов, которые пользователь должен ввести вручную. Многие CAPTCHA требуют от пользователя не только простого ввода данных с картинки, но и выполнения математических операция или манипуляций с объектами.
Современные OCR приложения распознавания сканированного текста могут распознавать даже рукописный текст – это актуально для сенсорных устройств, которые позволяют писать текст с помощью специального пера, а не клавиатуры.
Сам процесс распознавания сканированного текста проходит в три стадии: pre-processing (предварительная), само OCR распознавание, post-processing (последующая обработка).
При предварительной обработке целью является подготовить сканированный документ до наилучшего состояния – поворот, очистка от нежелательных точек и др. – так, чтобы последующий процесс распознавания текста был как можно более точным.
В ходе последующей обработки (post-processingu) текст проверяется согласно словарю для данного языка; автоматически, или при помощи пользователя, исправляются ошибки и неправильно распознанные символы.
Краткая история OCR распознавания текста

Вверху - шрифт OCR-A, внизу - OCR-B
Разработка OCR началась около 30 лет назад, тем не менее, эта технология распознавания текста достаточно неизвестная и мало распространенная. В гуманитарных областях, но и точных наук, в большинстве педагогических институтов, практически не используется. В самом начале технология оптического распознавания сканированного текста была связана с двумя крупными компаниями American Bankers Association и Financial Services Idustry, которые стремились к быстрой и качественной обработке финансовых документов, чеков, ценных бумаг. OCR технология была отличным решением, с течением времени, однако, была заменена на более динамичную технику MICR (Magnetic Ink Character Recognition).
В 1966 году в США произошла стандартизация так называемого шрифта OCR-A, который был первым шрифтом, позволяющим машинное чтение. Формы этого шрифта были упрощены, чтобы было само чтение как можно более точным, но шрифт не очень хорошо читается человеческим глазом. Шрифт OCR-A нашел применение в крупных банках. В Европе возникает вскоре после этого (1968) стандартный шрифт OCR-B и его автором был Адриан Фрутигер. Этот стандарт хуже читается машиной, но обеспечивает лучшую читаемость невооруженным глазом.
Первые OCR инструменты распознавания текста были очень медленными, и не давали требуемой точности. В основном, они ограничивались распознаванием специальных шрифтов OCR-A и OCR-B, со временем, однако, произошел их огромный бум. В 90-х годах произошло улучшение этой технологии. Увеличение производительности OCR значительно снизило цены на сканеры, технология стала легко доступной.
OCR программы и онлайн сервисы для распознавания текста

Для OCR распознавания сканированного текста можно использовать несколько различных инструментов. Вы можете воспользоваться как интернет приложениями, так и полноценными программами.
За качество надо платить. Попробовать trial-версии платных OCR программ для распознавания текста уже не так просто, как когда-то - их производители уже дали свой ответ на высокий уровень пиратства своего программного обеспечения выходом модели 30-дневных версий своего продукта, которые выполняют свою работу с ограниченными возможностями. К ним относятся два из лидеров на OCR рынке: OmniPage с поддержкой 123 языков, и Readiris с поддержкой ста двадцати языковых наборов. Одним из немногих приложений, которые в последней версии вы можете попробовать на собственной шкуре, ABBYY Fine Reader.
- FreeOCR. Хотя есть много онлайн инструментов для OCR распознавания текста, лучшим решением всегда остаются прикладные программы. Как вариант, можно попробовать воспользоваться бесплатным приложением FreeOCR. Оно не только приносит полновесные варианты распознавания, сохраняя структуру текста, но и поддерживает широкий спектр входных и выходных форматов.
- TopOCR – OCR программа распознавания текста из фотографий и других документов. Программа, которая может отлично распознавать текст с картинки или фотографии, и конвертировать его в читаемый вид. В результате текст можно конвертировать в другие форматы и редактировать. Текст можно конвертировать в форматы TXT, PDF, RTF и HTML.
- ABBYY FineReader. FineReader представляет собой настоящего профессионала и один из очень немногих действительно применимых решений при передаче фотографий, изображений или сканируемого текста. Его сила основана на действительно вдумчивой системе, которая стоит на трех основных столпах. OCR программа сначала разбивает изображение на области, в соответствии узнаваемых структур, те в свою очередь подразделяются на буквы и слова. После того, как текст разбивается на буквы, происходит их распознавание и сравнение целых слов со словарем. Затем выбирается наиболее подходящее решение. Еще один столп говорит о целесообразности, когда каждый текст имеет свой контекст, и на него нужно тоже обратить внимание. Последним и очень важным элементом является адаптация – OCR программа для распознавания текста должна уметь учиться с собственных действий.
Если вы не хотите устанавливать на компьютере программы, то можете использовать онлайн распознавание OCR.
OnlineOCR (www.onlineocr.net). Вероятно, лучший онлайн OCR конвертер, который вы можете встретить (хотя для раскрытия полного спектра функций вам необходимо бесплатно зарегистрироваться, иначе, вы будете ограничены количеством передаваемых документов, их размером и форматом). OnlineOCR поддерживает 32 языка. Сервис обладает отличной точностью распознавания текста и сохранения структуры документа.
NewOCR (www.newocr.com). NewOCR поддерживает 29 языков и анализ структуры текста. Истинное сохранение структуры, однако, не ждите, единственным результатом преобразования является только текст непосредственно в приложении, возможность прямого сохранения в DOC или RTF отсутствует – текст придется копировать вручную. В отличие от OnlineOCR, не нужно регистрироваться, ограничение на размер изображений установлено до 5 МБ. Фундаментальная проблема, однако, возникает при оценке точности транскрипции, тут онлайн распознавание OCR от NewOCR немного хромает.
Free OCR (www.free-ocr.com). Другим бесплатным и доступным онлайн OCR сервисом для распознавания текста является Free OCR. Позволяет конвертировать изображения до 2 МБ и одностраничные PDF, максимально 10 в час. Поддерживает 29 языков, наборов, без регистрации и приносит несравненно более высокую точность, чем предыдущий NewOCR. Структура текста, однако, также не сохраняется и позволяет экспортировать только чистый текст (без форматирования).
Спасибо за внимание. Автор блога Владимир Баталий